NBA Player Evaluation Using Ridge Regression and the Lasso
DATA622-Lab4
In this lab you are going to be using resampling techniques (cross-validation and the bootstrap) along with regularization (ridge regression and the lasso) to rank basketball players based on their performance during the 2022 NBA season. To get the most out of this lab, you do not need to be an expert on the NBA, but you do need to pay attention to the following background information.
Basketball is a sport played between two teams. Each team has 12 total players, but only 5 are on the court for each team at a given time. The goal of the game is to score more points than the other team during the 48 minutes of game time. Points are scored by “shooting” a ball into a 10 foot tall metal hoop called the “basket”. If you want to watch the gameplay, [skim this video]. Or, you can watch [this 8 minute video that explains the rules].
Traditionally, basketball players have been evaluated based on their individual statistics, such as the number of points that they score in a game, the number of “rebounds” they get (a rebound is when a player catches the ball after a missed shot), the number of “steals” (when a player takes the ball from the other team), and more. However, basketball is a complicated team sport, and the actions of all five players on a team contribute to these individual statistics.
The goal of capturing these more abstract contributions to success has led to the concept of “plus-minus”, which looks at how the presence or absence of a player on the court correlates with the scoring margin of the team. The idea is to model what happens in a basketball game by assigning each player on both teams a “coefficient”, which will be called “RAPM” during this homework assignment. “RAPM” stands for Regularized Adjusted Plus Minus, and it measures the contribution of each player to the expected point differential between the two teams. A player with a RAPM of 3 is expected to add 3 points to their team’s net performance for every 100 possessions of a basketball game (a possession is defined as a period of the game where a single team has control of the ball, games consist of a series of alternating possessions and there are usually about 200 possessions in a game, 100 per team).
Suppose that two teams are playing against each other, and that the “lineups” of the two teams stay the same for a certain number of possessions, call it num_pos. This period of time with constant lineups is called a stint, and we can model the probability distribution for the point “margin”, defined as:
Here, the sum is over all the different players in the dataset, and the coefficient \(c_{ij}\) is +1 if that player \(j\) was on the court during stint \(i\) and playing for the “home” team, and -1 if they were on the court for the “road” team. The coefficient is \(0\) otherwise. The “home” team and “road” team distinction allows us to use the same data for players who were playing against each other. The “margin” variable is the point differential during the stint normalized to points per 100 possessions.
Here you can see that each row corresponds to a stint where the players on the court didn’t change. The n_pos variable is the number of possessions that took place during that stint. The home_points and away_points are the number of points scored by the home and away teams respectively. The minutes describes how long in minutes the stint lasted, and the margin is the target variable (defined earlier). The features in column 7 onwards are labeled by player ids, and the value in each cell corresponds to the \(c_i\) values for that stint (whether the player was on the court for the home team, road team, or neither). You can recover the identity of the players from the [player_id] file.
In the following you will be exploring different ways of calculating the the RAPM model coefficients and interpreting them in terms of player skill.
Problem 1: Ridge Regression for Inference
Ordinary Linear Regression:
Use ordinary linear regression to fit the model described in the overview. Use cross-validation to estimate the out of sample root mean squared error and compare it to the in sample error, you may use RidgeCV with \(alpha=1e-8\) to keep consistency with the rest of the assignment, or use LinearRegression. Make sure fit_intercept=True, the intercept corresponds to the home court advantage, and do not use sample_weight.
Does the difference between in-sample and cross-validated mean squared error suggest a major problem with overfitting?
Prep:
▐ The “target” (y variable) is $margin , and the “predictors” are the players- everything past column 7.
▐ The in-sample mean squared error was lower than the cross validated. This is because the predictions come directly from the training datapoints. The values are pretty close to each other with only a 0.06% difference. I don’t believe there is an overfitting problem here but by the nature of the in-sample measurement I would asusme the in-sample MSE would typically be lower than the cross validated.
Examining RAPM Coefficients:
Create a dataframe with the player-ids, the RAPM coefficients, and join it with the player names (from the data file shared earlier).
Use the stint matrix to calculate the number of minutes that each player played (minutes variable) and add that to the data frame too.
Sort the players in descending order by ‘RAPM’ and print the top 20 players by ‘RAPM’. What do you notice about their minutes played? Look up the names of a few of the top players on the internet- are they regarded as top NBA players?
Make a scatter plot of RAPM versus minutes-played.
#--Player id df--players= pd.read_csv("https://raw.githubusercontent.com/georgehagstrom/DATA622Spring2026/refs/heads/main/website/assignments/labs/labData/player_id.csv")#--Model RAPM Coefficients--rapm=dict(zip(x.columns.astype(int), m1.coef_))players["rapm"]= players["player_id"].map(rapm)#--Join Stints--#stint matrixstints2= stints.iloc[:,7:]minutes= stints["minutes"].values#-- using absolute value because of the "road" -1s--stints2=abs(stints2).T#--Calculate minutes--players2= (stints2 * stints["minutes"].values).sum(axis=1)players2=players2.to_frame(name="t_minutes")players2.index.name="player_id"players2= players2.reset_index().astype(int)#-- Joining on players--players= players.merge(players2, on="player_id", how="left")players= players.sort_values("rapm", ascending=False)
▐ The player matrix stint x player, transposed, becomes player x stint. In this shape, we can multiply the array of minutes to produce the minutes played per stint. The result is the lineup below:
Top 20 Lineup: Linear Model
#-- The players have a headshot and the ID's are real!-- top20=pd.DataFrame(players.head(20))top20= top20.copy()#-- adding the ids to the base url--top20["image_url"]= top20["player_id"].astype(str).apply(lambda x: f"https://cdn.nba.com/headshots/nba/latest/1040x760/{x}.png")header="<h1 style='text-align:center;'>Top 20 by RAPM</h1>"p_cards ="".join(f"<div style='text-align:center;'>"f"<img src='{row.image_url}' style='width:90px;'>"f"<div style= 'font-size:13px;font-weight: bold'>{row.player_name}</div>"f"<div style= 'font-size:12px;'>RAPM: {row.rapm:.3f}</div>"f"<div style= 'font-size:12px;'>Play Time: {row.t_minutes}</div>"f"</div>"for player, row in top20.iterrows())HTML(f"<div style='display:grid;grid-template-columns:repeat(5,1fr); gap:8px;'>{p_cards}</div>")
Stanley Umude
RAPM: 77.399
Play Time: 2
Jordan Schakel
RAPM: 62.877
Play Time: 6
Marko Simonovic
RAPM: 50.272
Play Time: 18
Alize Johnson
RAPM: 50.138
Play Time: 28
Deonte Burton
RAPM: 47.435
Play Time: 7
Donovan Williams
RAPM: 47.427
Play Time: 4
Isaiah Mobley
RAPM: 41.990
Play Time: 87
Nikola Jokic
RAPM: 37.628
Play Time: 2255
Kendall Brown
RAPM: 37.509
Play Time: 38
Jalen Brunson
RAPM: 36.865
Play Time: 2406
Dereon Seabron
RAPM: 36.223
Play Time: 11
Luka Samanic
RAPM: 36.063
Play Time: 140
Mfiondu Kabengele
RAPM: 34.273
Play Time: 41
Ron Harper Jr.
RAPM: 33.438
Play Time: 46
Xavier Cooks
RAPM: 33.412
Play Time: 117
Devon Dotson
RAPM: 33.313
Play Time: 50
Miles McBride
RAPM: 33.030
Play Time: 773
Tyrese Martin
RAPM: 33.015
Play Time: 63
Jarrell Brantley
RAPM: 32.954
Play Time: 33
Mac McClung
RAPM: 32.606
Play Time: 44
▐ I’m not familiar with the NBA, but I can accurately say Lebron James is not in this lineup! In my research the players don’t seem to be very well known. If we take a closer look, Stanley Umunde’s stats would make him legendary. An RAPM of 77 would mean Stanley is expected to add 77 points to his team’s net per 100 possessions, and this is based on 2 minutes of total play time. The linear model might be overfitting.
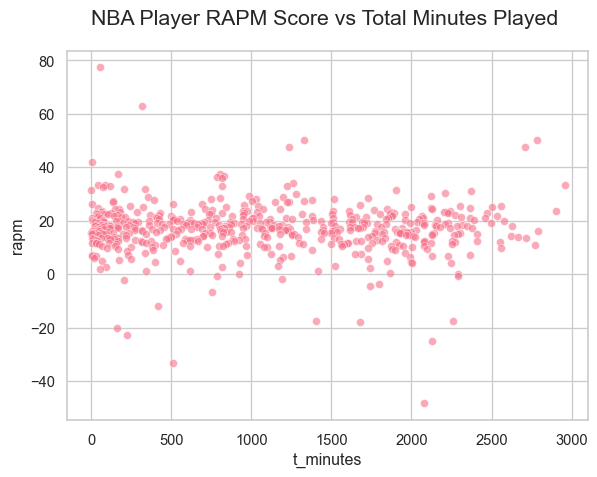
#-- fixing sns--sns.set_theme(style="whitegrid", palette="husl")plt.rcParams["axes.titlesize"] =16plt.rcParams["axes.titlepad"] =20#-- Visualize RAPM--sns.scatterplot(data= players, x="t_minutes", y="rapm", alpha=0.6)plt.title("NBA Player RAPM Score vs Total Minutes Played ")plt.show()
▐ The scatterplot shows the linear relationship between rapm and t_minutes is weak and near zero. Its funnel shaped because the data points near zero playtime have a large range. This variability suggests this an issue in the RAPM calculations.
Ridge Regression RAPM:
The results of (b) suggest that the model is attaching extreme values of RAPM to low minute players, something which can be potentially fixed with regularization. Define a vector of regularization parameters alpha on a logarithmic scale between \(10^{-2}\) and \(10^{5}\) (look up np.logspace).
Make this vector contain at least 10 but not more than 200 values of alpha (pick based on how fast your computer is). Use RidgeCV to fit a ridge regression model, selecting the model with the best value of the hyperparameters.
What value of alpha is optimal? Next, repeat the same calculation as you did in part (b) (you could create a function or just copy the dataframe and replace the old RAPM with new RAPM). Look up some of the top players that your model identified, are they well regarded by the NBA?
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
#--pulling the ridge values--rapm2=dict(zip(x.columns.astype(int), m2.coef_))players["rapm2"]= players["player_id"].map(rapm2)players= players.sort_values("rapm2", ascending=False)top20=pd.DataFrame(players.head(20))top20= top20.copy()#-- adding the ids to the base url--top20["image_url"]= top20["player_id"].astype(str).apply(lambda x: f"https://cdn.nba.com/headshots/nba/latest/1040x760/{x}.png")header="<h1 style='text-align:center;'>Model 2: Top 20 by RAPM (Ridge)</h1>"p_cards ="".join(f"<div style='text-align:center;'>"f"<img src='{row.image_url}' style='width:90px;'>"f"<div style= 'font-size:13px;font-weight: bold'>{row.player_name}</div>"f"<div style= 'font-size:12px;'>RAPM: {row.rapm2:.3f}</div>"f"<div style= 'font-size:12px;'>Play Time: {row.t_minutes}</div>"f"</div>"for player, row in top20.iterrows())HTML(f"<div style='display:grid;grid-template-columns:repeat(5,1fr); gap:8px;'>{p_cards}</div>")
Joel Embiid
RAPM: 5.653
Play Time: 2249
Nikola Jokic
RAPM: 4.916
Play Time: 2255
Trae Young
RAPM: 4.692
Play Time: 2706
Pascal Siakam
RAPM: 4.258
Play Time: 2497
Kevin Love
RAPM: 3.862
Play Time: 1131
Jalen Brunson
RAPM: 3.852
Play Time: 2406
Draymond Green
RAPM: 3.761
Play Time: 2019
Brook Lopez
RAPM: 3.516
Play Time: 2156
Zion Williamson
RAPM: 3.506
Play Time: 859
Anthony Davis
RAPM: 3.385
Play Time: 1880
Coby White
RAPM: 3.364
Play Time: 1795
Kawhi Leonard
RAPM: 3.353
Play Time: 1817
Derrick White
RAPM: 3.302
Play Time: 2078
Darius Garland
RAPM: 3.279
Play Time: 2209
Julius Randle
RAPM: 3.266
Play Time: 2956
Myles Turner
RAPM: 3.220
Play Time: 1676
Isaiah Joe
RAPM: 3.118
Play Time: 1553
Jrue Holiday
RAPM: 3.027
Play Time: 2097
Michael Porter Jr.
RAPM: 2.952
Play Time: 1686
Franz Wagner
RAPM: 2.951
Play Time: 2293
▐ Ridge regression changed the top 20 significantly. The RAPM scores are lower, ranging from ~2.9 to 5.7, instead of high 30s and 40s. The players for the most part have higher play times which (intuitively) is more reliable.
The scatter plot below shows the model RAPM scores against total minutes played. The scatter is correctly gathering near zero RAPM for players whose time played is also near zero. On the other end players who have spent more time on the court have varied RAPM scores, so being on the court longer isn’t necessarily equal to high RAPM, which is a good thing. Overall, this Ridge model is probably more accurate than the Linear Model in Problem 1.
#-- Visualize RAPM--sns.scatterplot(data= players, x="t_minutes", y="rapm2", alpha=0.6)plt.title("NBA Player RAPM Score vs Total Minutes Played ")plt.show()
Problem 2: Possession Weights
Heteroscedasticity in Stints:
Make a plot of the margin variable as a function of the number of possessions in a stint. What do you notice about the variance of margin? Why do you think it is happening?
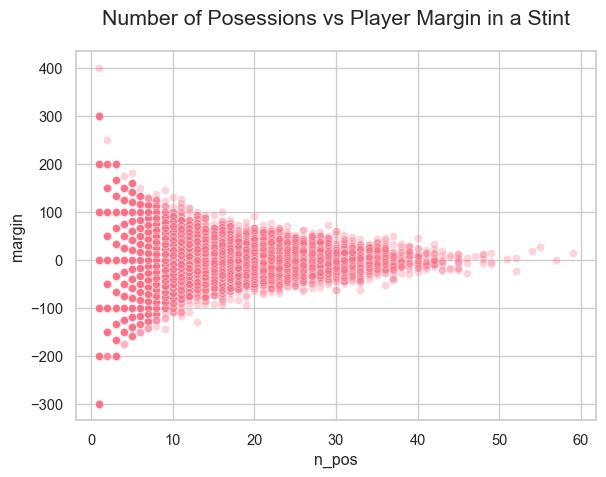
▐ The plot below is a funnel shaped. Low possession are highly variable, while high possessions are not. Its lack of contant variance is characteristic of heteroscedasticity.
sns.scatterplot(data=stints, x="n_pos", y="margin", alpha=0.3)plt.title("Number of Posessions vs Player Margin in a Stint")plt.show()
Implementing Weights Regression:
The solution to the issue that you observed in 2(a) is something called weighted least squares This involves adjusting the error term for each stint, based on a weight that accounts for whatever factor controls the variance.
where \(w_i\) is a coefficient that determines how the variance of margin should scale for each stint. The idea is that \(w_i\) should be smaller for stints where the variance is high, and larger for stints where the variance is low. This forces the model to fit the low-variance stints more closely than the high-variance stints. The correct weights for this problem are the \(w_i = \mathrm{num\_pos}_i\), which implies that the variance of the margin is inversely proportional to the number of stints.
Verify this by making a scatter plot of the margin rate times the square root of the number of possessions versus the number of possessions.
Then recalculate the player RAPM coefficients from 1(c) by setting the weights keyword in the model fit to be n_pos. How have the rankings of top players changed?
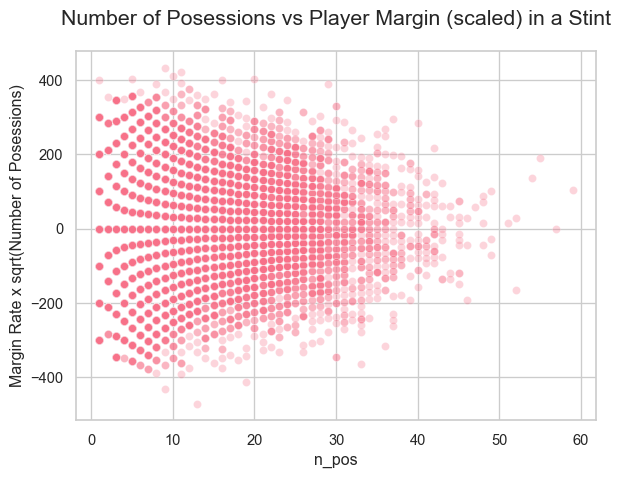
Scatterplot for Scaled Margin
▐ Using weighted least squares has helped the heteroscedasticity seen in the scatter plot above. Although it is still slightly funnel shaped, the new plot below has a more uniform variance.
sns.scatterplot(data=stints, x="n_pos", y=stints["margin"] * np.sqrt(stints["n_pos"]), alpha=0.3)plt.title("Number of Posessions vs Player Margin (scaled) in a Stint")plt.ylabel("Margin Rate x sqrt(Number of Posessions)")plt.show()
#-- adding the ids to the base url p3--top20["image_url"]= top20["player_id"].astype(str).apply(lambda x: f"https://cdn.nba.com/headshots/nba/latest/1040x760/{x}.png")header="<h1 style='text-align:center;'>Model 3: Top 20 by RAPM (WLS)</h1>"p_cards ="".join(f"<div style='text-align:center;'>"f"<img src='{row.image_url}' style='width:90px;'>"f"<div style= 'font-size:13px;font-weight: bold'>{row.player_name}</div>"f"<div style= 'font-size:12px;'>RAPM: {row.rapm3:.3f}</div>"f"<div style= 'font-size:12px;'>Play Time: {row.t_minutes}</div>"f"</div>"for player, row in top20.iterrows())HTML(f"<div style='display:grid;grid-template-columns:repeat(5,1fr); gap:8px;'>{p_cards}</div>")
Nikola Jokic
RAPM: 2.782
Play Time: 2255
Draymond Green
RAPM: 2.645
Play Time: 2019
Joel Embiid
RAPM: 2.558
Play Time: 2249
Jrue Holiday
RAPM: 2.495
Play Time: 2097
Kawhi Leonard
RAPM: 2.295
Play Time: 1817
Giannis Antetokounmpo
RAPM: 2.274
Play Time: 1840
Aaron Gordon
RAPM: 2.097
Play Time: 1966
Anthony Davis
RAPM: 2.093
Play Time: 1880
Josh Hart
RAPM: 2.073
Play Time: 2474
Brook Lopez
RAPM: 1.885
Play Time: 2156
Christian Koloko
RAPM: 1.883
Play Time: 757
Derrick White
RAPM: 1.833
Play Time: 2078
Zion Williamson
RAPM: 1.821
Play Time: 859
Michael Porter Jr.
RAPM: 1.787
Play Time: 1686
Jayson Tatum
RAPM: 1.725
Play Time: 2771
Desmond Bane
RAPM: 1.702
Play Time: 1706
Nicolas Batum
RAPM: 1.577
Play Time: 1814
Austin Reaves
RAPM: 1.534
Play Time: 1901
Jarrett Allen
RAPM: 1.488
Play Time: 2076
Devin Booker
RAPM: 1.434
Play Time: 1904
▐ After adding number of possessions as the weighted variable to this model, the resulting Top 20 includes players I’ve heard of before— Devin Booker & Anthony Davis. Intuitively, the Rdigemodel with WLS is closer to being accurate in ranking the player, considering. In this top 20, RAPM scores are no higher than ~2.8 and all players have at least 12 hours of total play time.
Problem 3: Interpreting Bootstrap Uncertainty
Calculate Confidence Intervals Using the Bootstrap:
Suppose you are a general manager for a basketball team. You want to identify candidate players to add to your team, but you are unsure how certain to be about the RAPM coefficients for the model. The bootstrap is a standard approach for calculating confidence intervals for model coefficients.
Use either the resample function from sklearn or np.random.choice along with a loop to calculate bootstrap samples of the model coefficients for each player. You may use the optimal alpha found during the hyperparameter search in 2(b) for all bootstrap fits.
Do not forget to resample the weights when bootstrapping!
For the top 20 players, display the RAPM estimates along with the confidence interval (calculate 92% intervals or some other high value that isn’t 95%). How much do the intervals of the top 20 overlap?
#--matching the Player IDs--rapm4=dict(zip(x.columns.astype(int), m4.coef_))cil_map=dict(zip(x.columns.astype(int), np.percentile(boot, 4, axis=0)))ciu_map=dict(zip(x.columns.astype(int), np.percentile(boot, 96, axis=0)))#-- Adding the Cisplayers= players.copy()players["rapm4"]= players["player_id"].map(rapm4)players["ci_lower"]= players["player_id"].map(cil_map)players["ci_upper"]= players["player_id"].map(ciu_map)players= players.sort_values("rapm4", ascending=False)top20= players.head(20).copy()top20["ci_range"]= top20["ci_upper"]-top20["ci_lower"]
Top 20 Lineup: Confidence Interval
Code
#-- adding the ids to the base url p4--top20["image_url"]= top20["player_id"].astype(str).apply(lambda x: f"https://cdn.nba.com/headshots/nba/latest/1040x760/{x}.png")header="<h1 style='text-align:center;'>Model 4: Top 20 by RAPM (after Bootstrapping)</h1>"p_cards ="".join(f"<div style='text-align:center;'>"f"<img src='{row.image_url}' style='width:90px;'>"f"<div style= 'font-size:14px; font-weight: bold'>{row.player_name}</div>"f"<div style= 'font-size:12px;'>RAPM: {row.rapm4:.3f}</div>"f"<div style= 'font-size:12px;'>Play Time: {row.t_minutes}</div>"f"<div style= 'font-size:12px;'>CI:({row.ci_lower:.3f}, {row.ci_upper:.3f})</div>"f"<div style= 'font-size:14px; font-weight: bold'>CI Range:{row.ci_range:.3f}</div>"f"</div>"for player, row in top20.iterrows())HTML(f"<div style='display:grid;grid-template-columns:repeat(5,1fr); gap:8px;'>{p_cards}</div>")
Anthony Davis
RAPM: 8.120
Play Time: 1880
CI:(3.245, 9.094)
CI Range:5.849
Kawhi Leonard
RAPM: 8.016
Play Time: 1817
CI:(2.822, 8.038)
CI Range:5.216
Draymond Green
RAPM: 7.150
Play Time: 2019
CI:(3.054, 9.371)
CI Range:6.317
Isaiah Mobley
RAPM: 7.060
Play Time: 87
CI:(0.625, 7.141)
CI Range:6.516
Jonathan Isaac
RAPM: 6.968
Play Time: 160
CI:(-2.149, 5.778)
CI Range:7.927
Joel Embiid
RAPM: 6.725
Play Time: 2249
CI:(3.339, 8.745)
CI Range:5.406
Nikola Jokic
RAPM: 6.561
Play Time: 2255
CI:(3.837, 10.526)
CI Range:6.689
Tyler Herro
RAPM: 5.779
Play Time: 2181
CI:(0.360, 6.601)
CI Range:6.240
Miles McBride
RAPM: 5.776
Play Time: 773
CI:(-0.930, 6.017)
CI Range:6.947
Jayson Tatum
RAPM: 5.645
Play Time: 2771
CI:(1.188, 6.429)
CI Range:5.241
Zion Williamson
RAPM: 5.486
Play Time: 859
CI:(2.281, 8.356)
CI Range:6.075
Michael Porter Jr.
RAPM: 5.306
Play Time: 1686
CI:(0.068, 6.121)
CI Range:6.053
Kevin Huerter
RAPM: 5.280
Play Time: 1996
CI:(-0.151, 6.119)
CI Range:6.270
Giannis Antetokounmpo
RAPM: 5.208
Play Time: 1840
CI:(2.132, 8.045)
CI Range:5.914
Aaron Gordon
RAPM: 5.091
Play Time: 1966
CI:(0.813, 7.397)
CI Range:6.583
Jrue Holiday
RAPM: 5.038
Play Time: 2097
CI:(2.269, 7.696)
CI Range:5.427
Shaquille Harrison
RAPM: 5.035
Play Time: 136
CI:(-1.369, 5.358)
CI Range:6.727
Trae Young
RAPM: 4.999
Play Time: 2706
CI:(0.047, 5.268)
CI Range:5.221
Blake Griffin
RAPM: 4.954
Play Time: 501
CI:(-0.375, 6.551)
CI Range:6.926
Xavier Cooks
RAPM: 4.810
Play Time: 117
CI:(0.126, 6.479)
CI Range:6.353
▐ Most players fall within the same confidence intervals. The CI values here express the uncertainty within the sampling. Take the Top 2 picks, Cameron Johnson and Charles Bassey, for example. Cameron is assigned an RAPM of 7 with a 92% ci that his actual RAPM is between ~0.82 and 7.5. The range is far too wide at 6.06. Likewise, Charles’ range is a 6.5 so it’s uncertain what his true contribution to the team is.
Impact of Minutes Played on Confidence Intervals:
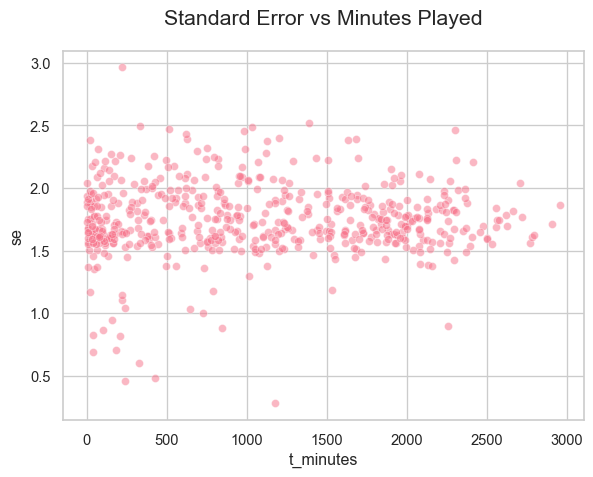
One potential use of a model like this is to find players who do not play much but who might do well with more opportunity. Calculate the standard errors of each coefficient from the bootstrap samples and make a scatterplot of standard error versus minutes played.
Comment on the relationship between minutes played and standard error- does it make sense to you intuitively and/or statistically?
players["se"]=np.std(boot, axis=0)
▐ The scatterplot below shows points <1500 minutes of play time have standard error values with high variability. Intuitively, the variability in the estimates of standard error, would decrease (the vertical spread of it) as players spend more time on the court as there is more stint data to consider. We see most points above 2500 minutes are less variable and gathered between 1.5 and 2.0.
sns.scatterplot(data=players, x="t_minutes", y="se", alpha=0.5)plt.title("Standard Error vs Minutes Played")plt.show()
Comparison to Bayesian Credible Intervals:
Bayesian statistics (which you should have learned about briefly in DATA 606) is a field of statistics based on an interpretation of probability as referring to uncertainty about the real world rather than as the frequency of outcomes in repeated experiments. In the Bayesian framework, it is normal to talk about the probability distribution of model parameters, which leads to the concept of a credible interval, defined as an interval with a certain probability of containing the model parameter (a 92% credible interval would have a 92% chance of containing the model parameter). Credible intervals often correspond closely to confidence intervals captured using standard statistics, but this problem is one case where they diverge sharply.
Ridge regression has an interpretation in Bayesian statistics, where the regularization parameter corresponds to the strength of a prior belief that the model coefficients have a normal distribution centered around zero and with variance inversely proportional to the regularization penalty \(\alpha\).
For ridge regression interpreted as Bayesian statistics, there is an exact formula for the standard errors and confidence intervals which we can use to contrast with the bootstrap estimate. I have provided code below to calculate the standard errors and the Bayesian credible intervals (if you are curious about the full details [read this article].
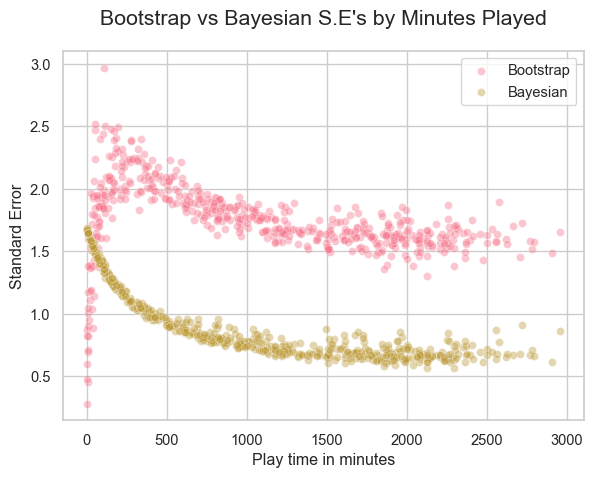
Use the code below and calculate the Bayesian standard errors for each ‘RAPM’ coefficient. Make a plot of the Bayesian standard errors versus minutes played and compare to the standard errors calculated from the bootstrap. In which part of the range is the agreement highest? In which part is the disagreement highest? Focusing on the areas where the disagreement is highest, put yourself in the shoes of someone using the model and discuss which estimate of uncertainty is more realistic and why.
(You will need to adapt the code below to your variable names and data structures.)
Code to calculate standard errors and Bayesian credible intervals
# Here MarginVector is your Target# StintMatrix are your observations# WeightVector are your weights# model_ridge is your selected model# alpha_opt is the optimal regularization parameter from cross validationx = stints.iloc[:,7:] y = stints["margin"]model_ridge = Ridge(alpha=m2.alpha_, fit_intercept=True)model_ridge.fit(x, y, sample_weight=stints["n_pos"])weights = stints["n_pos"].to_numpy() # Need to do this is WeightVector is a pandas series or df etcstint_mat = stints.iloc[:,7:] # Dittomargin_vec = stints["margin"] # Dittoalpha_opt= m2.alpha_var = np.average((margin_vec - model_ridge.predict(stint_mat))**2, weights=weights) # We need to incorporate weights into variance calculationnum_players = stint_mat.shape[1]AMat = (stint_mat * weights.reshape(-1, 1)).T @ stint_mat + alpha_opt * np.eye(num_players)# This is the covariance matrix. You could find very high covariance between players on the same teamsposterior_covariance = var * np.linalg.inv(AMat) se_vec = np.sqrt(np.diag(posterior_covariance)) #These are the standard errors
se_boot= np.std(boot, axis=0, ddof=1)se_boot_map=dict(zip(x.columns.astype(int), se_boot))players["se_boot"]= players["player_id"].astype(int).map(se_boot_map)se_bayes_map =dict(zip(x.columns.astype(int), se_vec))players["se_bayes"] = players["player_id"].astype(int).map(se_bayes_map)#--plotting--sns.scatterplot(data= players, x="t_minutes", y="se_boot", alpha=0.4, label="Bootstrap")sns.scatterplot(data= players, x="t_minutes", y="se_bayes", alpha=0.4, label="Bayesian")plt.xlabel("Play time in minutes")plt.ylabel("Standard Error")plt.title("Bootstrap vs Bayesian S.E's by Minutes Played")plt.legend()plt.show()
▐ The bootstrap standard errors come from our actual data, it has high variability at the lower end of total play time (<250). It stabilizes pasts 1500 minutes of play time and remains higher than the Bayesian scatter. The Bayesian standard errors are smooth and clean. Its regularization parameter being inversely proportional means that where we have our highest uncertainty/highest variability, the Bayesian se’s will pull the strongest in the opposite direction, so towards zero. This is why I think the Bayesian scatter is so tightly compact at the data’s widest.
Conclusion
Extra Credit (5 Points): Ridge versus Lasso and Confidence/Credible Interval Calculations
An alternative to ridge regression that is used for variable selection is called the Lasso. The Lasso differs penalty causes a large number of model coefficients to be zero, making it a good tool for variable selection and for creating interpretable models.
Use LassoCV to calculate the RAPM coefficients. I recommend using regularization weights that range between \(10^{-4}\) and \(10^2\) (the scale needs to be different compared to ridge regression).
Compare the RAPM values calculated with lasso to those calculated with ridge regression. Are there any notable differences in the top 20 players?
Find the 10 players with the largest difference between lasso RAPM and Ridge RAPM in both directions (ridge greater than lasso and lasso greater than ridge). Within the players where there was large disagreement, consider how the players performed in the next NBA season (you may do this however you like, I recommend reading media reports about those players during the next season) and determine which model was more correct when it comes to players with large disagreements.
There is a subtle conceptual flaw in how the confidence or credible intervals were calculated in this lab. This is apparent if you paid very close attention during the meetup. Can you tell me what it is?
▐ The Top 10 players with the highest Lasso to Ridge differences went on to win awards/titles like “All-Star” or “MVP” (except for those who had health issues1, or faced disciplinary action2). In comparison, the Ridge to Lasso most players ended up being traded or signing with another team or did not win an award in 2023 (except Jeff Green who had a great year
▐ The conceptual flaw in how the confidence intervals were calculated might be that they were calculated from a single alpha. Considering the alpha determines the penalty, it seems a little off that we’d select one alpha and sample 400 times without choosing another optimal alpha. Some samples might have many heavily penalized points while another might not be, which exacerbates the model uncertainty.